Redis网络模型
Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
(1)多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
那么为什么Redis是单线程的
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。

看到这里,你可能会气哭!本以为会有什么重大的技术要点才使得Redis使用单线程就可以这么快,没想到就是一句官方看似糊弄我们的回答!但是,我们已经可以很清楚的解释了为什么Redis这么快,并且正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!
但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
警告1:这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!例如Redis进行持久化的时候会以子进程或者子线程的方式执行(具体是子线程还是子进程待读者深入研究);例如我在测试服务器上查看Redis进程,然后找到该进程下的线程:
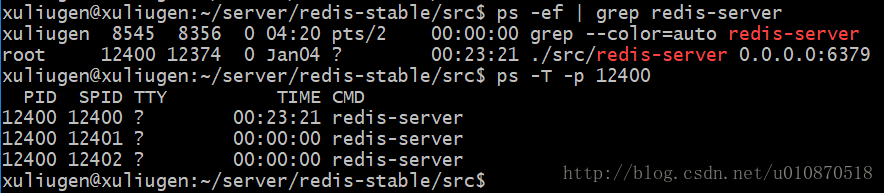
ps命令的“-T”参数表示显示线程(Show threads, possibly with SPID column.)“SID”栏表示线程ID,而“CMD”栏则显示了线程名称。
警告2:在上图中FAQ中的最后一段,表述了从Redis 4.0版本开始会支持多线程的方式,但是,只是在某一些操作上进行多线程的操作!所以该篇文章在以后的版本中是否还是单线程的方式需要读者考证!
注意点
1、我们知道Redis是用”单线程-多路复用IO模型”来实现高性能的内存数据服务的,这种机制避免了使用锁,但是同时这种机制在进行sunion之类的比较耗时的命令时会使redis的并发下降。因为是单一线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致并发的下降,不只是读并发,写并发也会下降。而单一线程也只能用到一个CPU核心,所以可以在同一个多核的服务器中,可以启动多个实例,组成master-master或者master-slave的形式,耗时的读命令可以完全在slave进行。
需要改的redis.conf项:
1
2
3
4
pidfile /var/run/redis/redis_6377.pid #pidfile要加上端口号
port 6377 #这个是必须改的
logfile /var/log/redis/redis_6377.log #logfile的名称也加上端口号
dbfilename dump_6377.rdb #rdbfile也加上端口号
2、“我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以手动地为其分配CPU核,而不会过多地占用CPU,或是让我们关键进程和一堆别的进程挤在一起。”。 CPU 是一个重要的影响因素,由于是单线程模型,Redis 更喜欢大缓存快速 CPU, 而不是多核
在多核 CPU 服务器上面,Redis 的性能还依赖NUMA 配置和处理器绑定位置。最明显的影响是 redis-benchmark 会随机使用CPU内核。为了获得精准的结果,需要使用固定处理器工具(在 Linux 上可以使用 taskset)。最有效的办法是将客户端和服务端分离到两个不同的 CPU 来高校使用三级缓存。